
Transform Your Business with Generative AI Services
Oodles delivers enterprise-grade Generative AI Services built on modern AI technologies including GPT-4, Claude, Gemini, LLaMA, and open-source foundation models. Our solutions combine Python, LangChain, vector databases, RAG architectures, secure APIs, and cloud-native infrastructure to build scalable, production-ready generative AI systems for enterprises.
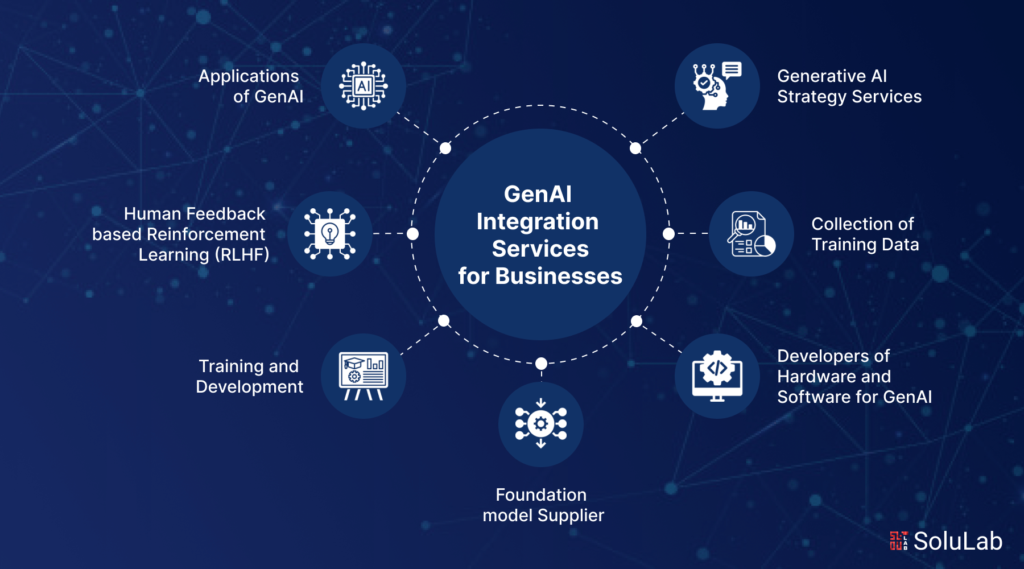
What are Generative AI Services?
Generative AI Services cover the complete lifecycle of designing, building, integrating, and deploying AI systems capable of generating text, images, code, and multi-modal outputs. These services leverage large language models, diffusion models, and transformer-based architectures implemented using Python, PyTorch, TensorFlow, and Hugging Face frameworks.
At Oodles, our Generative AI Services include prompt engineering, fine-tuning, Retrieval-Augmented Generation (RAG), vector database integration (Pinecone, FAISS, Chroma), API orchestration, and secure deployment using Docker, Kubernetes, and major cloud platforms such as AWS, Azure, and Google Cloud.
Why Choose Our Generative AI Services?
Oodles provides enterprise-ready Generative AI Services by combining advanced AI engineering with modern software architecture. Our team builds scalable AI solutions using Python, FastAPI, LangChain, LlamaIndex, vector databases, and cloud-native deployment pipelines to ensure reliability, security, and performance at scale.
- ✓ Multi-model support (GPT-4, Claude, Gemini, LLaMA, Stable Diffusion)
- ✓ Prompt engineering and domain-specific fine-tuning
- ✓ RAG pipelines with vector databases and document loaders
- ✓ Backend development using Python, FastAPI, Node.js
- ✓ Secure API deployment with authentication and monitoring
- ✓ Cloud-native and on-premise AI deployment
Enterprise-Grade Quality
Production-ready Generative AI systems built with tested frameworks, secure APIs, and monitored inference pipelines.
Rapid Development
Accelerated AI delivery using reusable prompt templates, LangChain workflows, and modular architectures.
Custom Solutions
Tailored generative AI pipelines using fine-tuning, RAG, and custom tool integrations.
Scalable Infrastructure
Cloud-native deployment using Docker, Kubernetes, AWS, Azure, and Google Cloud.
Our Generative AI Service Delivery Process
A systematic approach to delivering enterprise generative AI solutions from initial consultation to production deployment and ongoing optimization.
1
Use Case Analysis: Define objectives, evaluate datasets, and select models (GPT-4, Claude, Gemini, open-source LLMs).
2
Model Integration: Configure secure API access, embeddings, vector stores, and enterprise system integrations.
3
Custom Development: Implement prompt engineering, RAG pipelines, fine-tuning, and agent workflows using Python and LangChain.
4
Testing & Optimization: Evaluate outputs, latency, token usage, and model performance using automated testing and monitoring tools.
5
Production Deployment: Deploy scalable generative AI services with logging, rate limiting, security controls, and ongoing optimization.
Key Generative AI Service Capabilities
Conversational AI
Built using GPT-4, Claude, and Gemini APIs
Content Generation
Text, image, code, and multi-modal AI pipelines
RAG Systems
Vector databases, embeddings, document retrieval
Custom Fine-Tuning
Domain-adapted models using PyTorch & Hugging Face
Enterprise Integration
APIs, databases, CRMs, internal tools
Security & Compliance
Private deployments, access control, audit logging
FAQs (Frequently Asked Questions)
Text generation, image synthesis, code assistance, chatbots, RAG systems, and custom model integration. End-to-end consultation, development, and deployment for scalable enterprise AI.
Evaluation, testing, guardrails, and observability. We deliver scalable APIs, monitoring, and documentation. Follow enterprise SDLC and compliance standards for deployment.
Yes. We integrate with CRM, ERP, CMS, APIs, and internal tools. Design for your architecture. Ensure seamless data flow and workflow automation.
Fixed-price for defined scope, time & materials for evolving work, or dedicated team. We offer discovery, POC, and ongoing support depending on your needs.
Encryption, access controls, private hosting, and compliance frameworks. Support on-prem and VPC for regulated industries. No training on your data without consent.
Documentation, handoff, and optional retainer. Monitoring, prompt tuning, model updates, and incident response. Ongoing optimization for performance and cost.
Healthcare, fintech, legal, retail, media, SaaS, and support. Any sector needing automation, content creation, or intelligent workflows benefits from strategic GenAI adoption.
Ready to transform your business with Generative AI? Let's talk



We are ISO 9001:2015 Certified
Connect with us


Follow us
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()