
Intelligent Document Processing with Amazon Textract
Amazon Textract is a fully managed AWS OCR service that uses deep learning to extract text, handwriting, tables, and structured data from scanned documents and PDFs. Built on AWS AI infrastructure, Textract integrates seamlessly with Python-based workflows and AWS services such as Amazon S3, AWS Lambda, DynamoDB, OpenSearch, and Amazon Comprehend for scalable document automation.
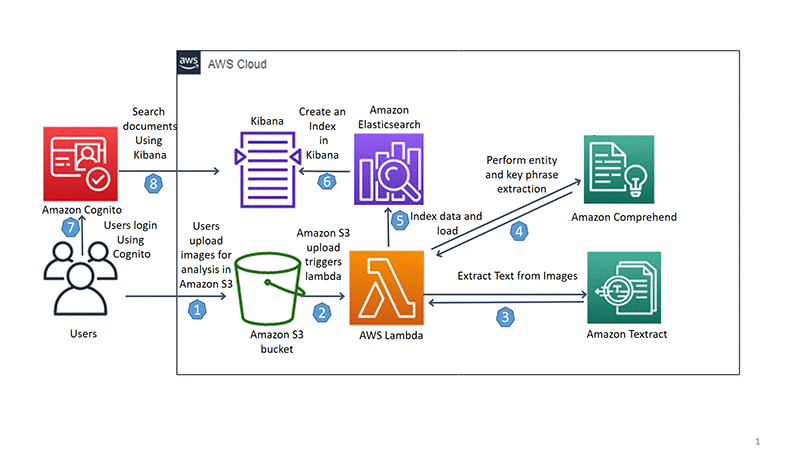
What is Amazon Textract?
Amazon Textract is an AWS-managed OCR and document analysis service that applies computer vision and deep learning models to extract structured and unstructured data from documents. It is commonly accessed using Python (Boto3 SDK) and REST APIs, enabling developers to automate document workflows without training custom machine learning models.
Core Capabilities of Amazon Textract
📄 OCR Text Extraction
Extract printed text and handwriting from scanned documents and images using deep learning OCR models managed by AWS.
📊 Table Recognition
Automatically detect and extract tables while preserving rows, columns, and cell relationships without templates.
📋 Form & Key-Value Extractio
Identify form fields, key-value pairs, checkboxes, and selection elements from complex document layouts.
✍️ Handwriting Recognition
Accurately process handwritten notes, forms, and annotations across multiple document types.
🔍 Document Structure Analysis
Understand document layout including paragraphs, headers, lists, and semantic groupings for downstream automation.
⚡ Scalable Processing
Run real-time or batch document processing using AWS-managed, auto-scaling infrastructure.
How Amazon Textract Works
End-to-end AWS-native document processing workflow
1
Document Ingestion: Documents are uploaded to Amazon S3 or sent directly via Textract APIs using Python (Boto3) or REST.
2
OCR & ML Analysis: AAWS deep learning models analyze text, tables, and forms without requiring custom model training.
3
Structured Output: Extracted data is returned as structured JSON with confidence scores for each detected element.
4
AWS Integration: Results are processed using AWS Lambda, stored in DynamoDB, indexed in OpenSearch, or analyzed with Amazon Comprehend.
5
Validation & Automation: Apply business rules, compliance checks, and workflow automation for enterprise use cases.
Why Choose Amazon Textract?
🎯 High OCR Accuracy
Deep learning OCR models trained on millions of documents deliver industry-leading accuracy
🚀 No ML Setup
No model training or infrastructure management required—just API calls.
🚀 No ML Expertise Required
Start extracting data immediately without training models.
🔒 Enterprise Security
AWS-grade security with IAM, encryption, VPC, and regulatory compliance.
📈 Scalable by Design
Process single documents or millions per month with consistent performance.
🔗 AWS Integration
Seamlessly integrate with other AWS services like S3, Lambda, DynamoDB, Comprehend, and SageMaker for end-to-end intelligent solutions.
Amazon Textract in Action
See how AWS-powered Amazon Textract enables scalable, secure, and automated document processing solutions across industries.

Amazon Textract Use Cases
Transform your document processing across industries
Financial Services - Invoice & Receipt Processing
Oodles builds intelligent invoice and receipt processing systems using Amazon Textract, AWS Lambda, and DynamoDB to automate financial workflows, reduce manual effort, and improve data accuracy.
Healthcare - Medical Records Digitization
Oodles leverages Amazon Textract with HIPAA-compliant AWS services to digitize medical records, extract patient data, and enable secure healthcare document automation.
Legal - Contract Analysis & Review
Using Amazon Textract and AWS-native analytics, Oodles develops contract intelligence solutions that extract clauses, dates, and legal entities from large volumes of legal documents.
Government - Form Processing & Citizen Services
Digitize government forms, applications, permits, and citizen documents for faster processing, improved service delivery, and reduced operational costs.
Enterprise - Document Management Systems
Build searchable document archives by extracting and indexing content from legacy documents, contracts, records, and business correspondence.
Logistics - Shipping Document Processing
Automate processing of bills of lading, customs forms, shipping manifests, and delivery receipts to streamline supply chain operations and reduce errors.
Ready to Deploy Amazon Textract? Let's Talk



We are ISO 9001:2015 Certified
Connect with us


Follow us
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()