
Enterprise-Grade Speech-to-Text (STT) Solutions
Convert speech into accurate, searchable text using enterprise-grade Speech-to-Text (STT) systems built with Python-based deep learning models and optimized C/C++ inference engines. Oodles delivers secure, scalable, and real-time automatic speech recognition solutions supporting 100+ languages, speaker diarization, custom vocabularies, streaming transcription, and on-premise deployments.
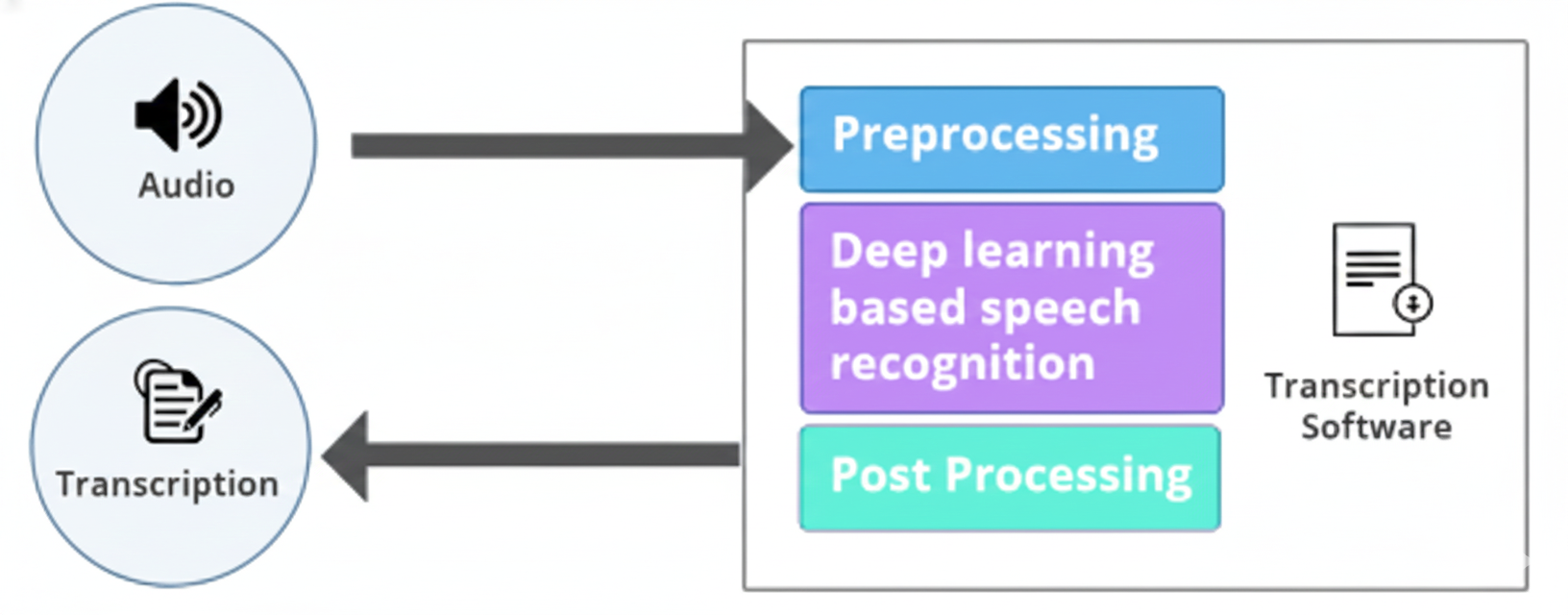
What is Speech-to-Text (STT)?
Speech-to-Text (STT), also known as Automatic Speech Recognition (ASR), converts spoken audio into written text using deep learning techniques. Modern STT systems are primarily developed in Python for model training and orchestration, while C and C++ are used for high-performance audio processing and low-latency inference. At Oodles, we build production-ready STT solutions using Whisper, DeepSpeech, NVIDIA NeMo, and cloud-native ASR engines, fine-tuned for accents, background noise, and domain-specific terminology.
Key Features of Our Advanced Speech-to-Text Solutions
Multilingual Support (100+ Languages)
Seamlessly transcribe conversations in English, Hindi, Spanish, Arabic, French, German, and more with high accuracy.
Speaker Diarization
Automatically identify and label multiple speakers in meetings, interviews, and calls for clearer context.
Real-Time Streaming
Live transcription powered by Python-based streaming pipelines and optimized C/C++ inference for low-latency speech recognition.
Custom Vocabulary & Fine-Tuning
Improve transcription accuracy using Python-driven fine-tuning pipelines and domain-specific language models for medical, legal, and technical speech.
Noise Robustness
Advanced noise-cancellation technology ensures accurate transcription even in noisy environments.
Punctuation & Formatting
Automatically adds punctuation, capitalization, and formatting to produce clean, readable transcripts.
Real-World Applications
Call Center Analytics
Transcribe customer calls, extract insights, and improve agent performance.
Meeting Transcription & Summarization
Auto-transcribe Zoom, Teams, Google Meet with speaker labels and action items.
Voice Assistants & IVR
Power voice bots with accurate speech recognition and natural conversation flow.
Media & Content Indexing
Transcribe podcasts, videos, interviews for search and subtitles.
Medical & Legal Documentation
Clinical notes, court proceedings, compliance recording with domain-tuned models.
On-Premise & Air-Gapped Deployments
Deploy on-premise STT systems using Python APIs and containerized inference engines.
Technologies & Models We Work With
We leverage state-of-the-art Speech-to-Text technologies and models to deliver accurate, scalable, and customizable transcription solutions for a wide range of industries.
OpenAI Whisper
From Tiny to Large-v3, Whisper provides high-accuracy, multilingual transcription with deep learning models.
DeepSpeech
An open-source STT engine optimized for speed and accuracy, ideal for custom deployments.
Google Cloud STT
High-performance, scalable cloud transcription with support for multiple languages and real-time streaming.
Amazon Transcribe & Medical
Cloud-based STT services with medical-specific models for HIPAA-compliant healthcare applications.
Microsoft Azure Speech
Enterprise-grade cloud STT with real-time transcription, speaker recognition, and customizable models.
NVIDIA NeMo
State-of-the-art neural modules for speech recognition, enabling custom and research-grade models.
Custom Fine-Tuned Models
Tailor-made STT models for industry-specific terminology and highly accurate transcriptions.
FAQs (Frequently Asked Questions)
Speech-to-Text services convert spoken audio into accurate written text using Automatic Speech Recognition (ASR) technology, enabling transcription, voice commands, analytics, and AI-driven automation.
Enterprise Speech-to-Text solutions deliver high transcription accuracy with noise reduction, speaker diarization, punctuation restoration, and custom vocabulary training for industry-specific use cases.
Yes, real-time Speech-to-Text systems provide live transcription for meetings, webinars, call centers, podcasts, and voice-enabled applications with low latency and scalable performance.
Modern Speech-to-Text platforms support multilingual transcription and automatic language detection, enabling global communication and localization across multiple languages and accents.
Speech-to-Text solutions integrate via APIs, cloud services, or on-premise deployments to enhance CRM systems, analytics platforms, voice assistants, and AI-powered business workflows.
Enterprise Speech-to-Text systems use encrypted APIs, secure cloud infrastructure, role-based access control, and compliance-ready architecture to protect sensitive voice and transcription data.
Professional Speech-to-Text development ensures optimized ASR model selection, custom vocabulary training, scalable deployment, performance tuning, and measurable ROI for voice-enabled AI applications.
Ready to transform your audio into text? Let’s get in touch



We are ISO 9001:2015 Certified
Connect with us


Follow us
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()