
Enterprise Tesseract OCR Software Development
Oodles designs and engineers enterprise-grade Tesseract OCR software using Python, C++, and OpenCV to automate text extraction from scanned documents, images, and PDFs. Our OCR software leverages the Tesseract LSTM engine, optimized image preprocessing, and API-driven architectures to deliver scalable, production-ready Optical Character Recognition systems.
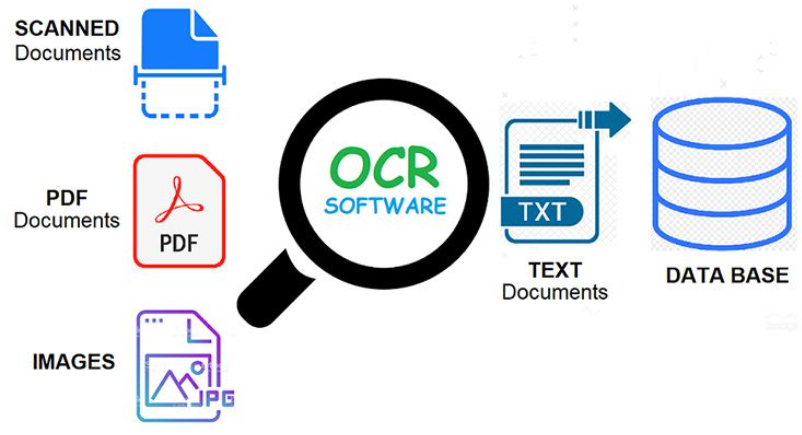
How Tesseract OCR Software Works
Tesseract OCR software converts visual text into machine-readable data
using a combination of image preprocessing, character segmentation,
and deep learning-based recognition. At Oodles, our Tesseract OCR
software pipelines are implemented in Python and C++ with OpenCV-powered
preprocessing for noise reduction, skew correction, and binarization.
Text recognition is performed using the Tesseract LSTM neural network
engine, after which extracted text is validated, normalized, and
structured for seamless integration with databases, enterprise
applications, and analytics platforms.
Core Components of Tesseract OCR Software
Image Preprocessing Engine
OpenCV-based preprocessing implemented in Python and C++, including denoising, grayscale conversion, adaptive thresholding, and skew correction to improve OCR accuracy.
Tesseract LSTM Recognition Engine
Optical Character Recognition powered by the Tesseract OCR engine using LSTM neural networks for printed, handwritten, and multi-font text recognition.
Document Layout Analysis
Layout-aware OCR software for detecting zones, tables, forms, and multi-column document structures.
Text Post-Processing & Validation
OCR output cleanup, normalization, and validation using rule-based logic and NLP libraries written in Python.
Software Integration Layer
REST-based OCR APIs and microservices for integrating Tesseract OCR software with enterprise databases, ERPs, and document management systems using JavaScript and Python.
Edge & Cloud Runtime
Containerized Tesseract OCR software deployments using Docker across cloud, virtual machine, and edge computing environments.
Tesseract OCR Use Cases
Oodles builds Tesseract OCR software that transforms unstructured document images into structured, searchable digital data.
Financial Document Processing
OCR software for invoices, bank statements, tax forms, and compliance documents.
Healthcare Records Digitization
Digitization of prescriptions, lab reports, and handwritten medical records.
Legal Document OCR
Searchable OCR software for contracts, court filings, and legal archives.
Logistics & Supply Chain
Text extraction from shipping labels, manifests, and delivery documentation.
Retail & Receipt OCR
Automated receipt scanning and structured data extraction software.
Multi-Language OCR Software
OCR software supporting 100+ languages using trained Tesseract language models.
FAQs (Frequently Asked Questions)
Tesseract OCR software uses LSTM-based recognition and advanced image preprocessing to extract text from scanned documents, PDFs, and images with high accuracy and structured output.
Tesseract OCR supports multilingual recognition, layout analysis, custom model training, and integration with automation systems for scalable enterprise document processing.
Tesseract OCR integrates through APIs and backend services with ERP, CRM, document management systems, and AI workflows to enable automated text extraction and data entry.
Optimization includes deskewing, noise reduction, image enhancement, custom language training, and layout detection to accurately process invoices, forms, and structured documents.
Tesseract OCR supports over 100 languages and custom language packs, enabling accurate multilingual text extraction for global enterprise applications.
Tesseract OCR can be deployed on-premise or in secure cloud environments, ensuring data privacy, encrypted processing, and compliance with enterprise security standards.
Tesseract OCR software reduces manual data entry, accelerates document processing, improves accuracy, and supports scalable digital transformation initiatives.
Need a dedicated team for Tesseract OCR Software? Let's talk



We are ISO 9001:2015 Certified
Connect with us


Follow us
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()