
Fine-Tune Large Language Models Efficiently with PEFT
Oodles helps enterprises specialize large language models using Parameter-Efficient Fine-Tuning (PEFT) techniques such as delivering LoRA, QLoRA, adapters, prefix tuning, and prompt tuning—delivering domain-aligned performance without the cost, risk, or infrastructure overhead of full model retraining. Our PEFT pipelines are built using PyTorch, Hugging Face Transformers & PEFT, bitsandbytes quantization, Accelerate, DeepSpeed, and modern evaluation frameworks—enabling faster iteration, lower GPU memory usage, and controlled, production-ready LLM deployments.
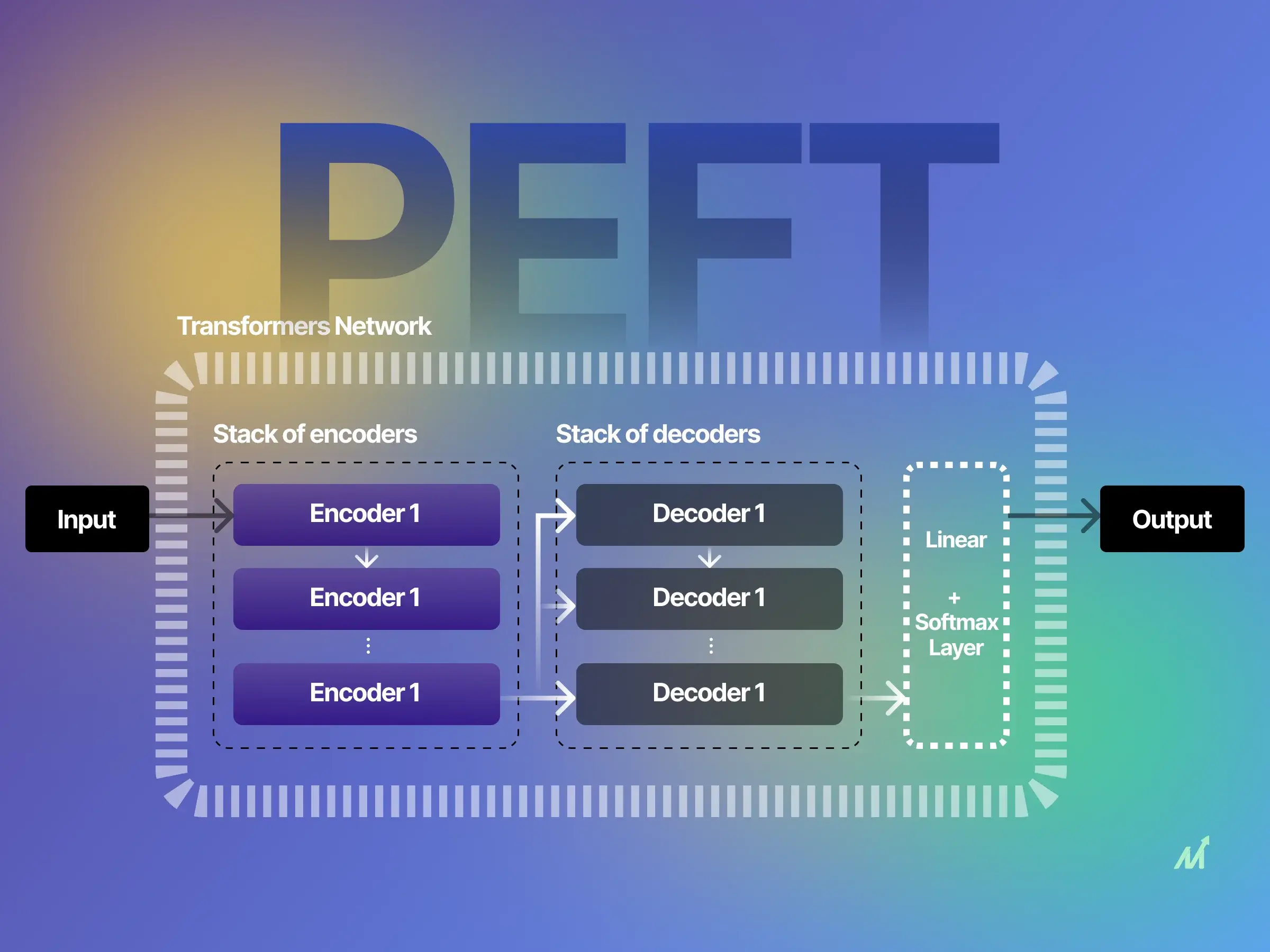
What Is PEFT?
Parameter-Efficient Fine-Tuning (PEFT) adapts large pre-trained transformer models by updating only a small subset of parameters—such as low-rank adapters, prefix vectors, or soft prompts—while keeping the base model frozen.
Oodles applies PEFT using LoRA, QLoRA, adapter layers, and prompt-based tuning combined with curated datasets, alignment strategies, and evaluation pipelines to deliver cost-efficient, reliable, and governable LLM solutions.
Why teams choose Oodles' PEFT approach
- ✓ Minimal GPU and VRAM requirements using LoRA, QLoRA, and quantized base models
- ✓ Rapid experimentation with reusable adapter checkpoints and versioned runs
- ✓ Safer deployments with policy enforcement, PII handling, and alignment controls
- ✓ Quality measurement using automated evals, golden datasets, and human-in-the-loop review
- ✓ Adapter artifacts compatible with common LLM inference runtimes and serving stacks
Efficient
Fewer trainable params
Controlled
Policy & safety baked-in
Measurable
Eval + human QA
Portable
Multi-cloud & hardware
PEFT Services
Engage the modules you need to specialize models without heavy retraining.
LoRA/QLoRA & Adapters
Design and train adapter stacks with proper rank/alpha settings and regularization for stability.
Prompt, Prefix, P-Tuning
Lightweight prompt-tuning strategies for fast iteration when full adapters are unnecessary.
Data & Alignment
Data selection, synthetic generation, de-duplication, red-teaming, and alignment targets for PEFT.
Evaluation & Safety
Eval harnesses, safety filters, hallucination/bias checks, and HIL review loops for sign-off.
Fine-Tuning Pipelines
Training pipelines, checkpoint management, experiment tracking, and versioned adapter storage tuned specifically for PEFT workflows.
Inference Optimization
Adapter merging, quantized base models, memory-efficient loading, and runtime optimization for PEFT-based inference.
How PEFT goes live
A clear path from scoping to production with checks for safety, quality, and cost.
1
Goals & Constraints: Define tasks, latency/quality targets, compliance needs, and hardware budget.
2
Data & Guardrails: Curate datasets, synthesize where needed, de-duplicate, and set safety/policy rules.
3
PEFT Strategy & Training: Choose LoRA/QLoRA, adapters, or prompt tuning; run experiments with tracking.
4
Evaluation & Safety Sign-off: Run task-specific evals, red-team, and human review; document release criteria.
5
Deploy & Monitor: Package adapters, integrate with the base model, and monitor quality, cost, and performance during inference.
Solutions & Use Cases
Where PEFT delivers immediate value.
Domain-tuned LLMs
Industry and product-specific adaptations using LoRA/QLoRA for accuracy without heavy retraining.
Customer Support Copilots
Grounded responses on policies and knowledge bases with safety filters and approval flows.
Compliance & Moderation
Policy enforcement bots, safety filters, and audit logging tuned to your risk framework.
Developer Productivity
Code copilots and review assistants aligned to your stack, style guides, and security rules.
Multilingual PEFT Adapters
Language- and region-specific adapters trained using PEFT techniques to localize terminology, tone, and domain behavior.
FAQs (Frequently Asked Questions)
PEFT (Parameter-Efficient Fine-Tuning) services optimize large language models by updating only a small subset of parameters using LoRA, QLoRA, and adapters, reducing compute costs while maintaining high model performance.
PEFT minimizes GPU usage by fine-tuning lightweight adapter layers instead of full model weights, enabling faster training cycles, lower memory consumption, and cost-efficient AI deployment.
Popular PEFT techniques include LoRA, QLoRA, adapters, prefix tuning, and prompt tuning, enabling scalable customization of foundation models for enterprise AI applications.
Yes, PEFT enables enterprise-grade LLM deployment by improving efficiency, reducing infrastructure costs, and ensuring scalable performance across cloud and on-prem environments.
PEFT enhances domain accuracy by adapting large language models to industry-specific datasets without retraining the full model, ensuring contextual relevance and reliability.
PEFT supports scalable AI by enabling lightweight fine-tuning, faster inference, reduced storage requirements, and seamless integration with MLOps pipelines.
Professional PEFT services ensure optimized fine-tuning strategies, robust evaluation frameworks, reduced hallucinations, and production-ready LLM deployment.
Ready to optimize your models with PEFT? Let's talk



We are ISO 9001:2015 Certified
Connect with us


Follow us
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()