
All About Machine Learning Algorithms and Their Enterprise Applications
Sanam Malhotra | 23rd June 2020

At the threshold of a new decade, artificial intelligence and its subset, machine learning promise a future led by rapid algorithmic advancements. However, machine learning development for enterprises requires a comprehensive understanding of the underlying machine learning algorithms and techniques.
Oodles AI shares this elaborative guide for choosing the right ML algorithm to build enterprise-grade applications.
Comprehending Machine Learning and its Types
“AI and its offshoot, machine learning, will be a foundational tool for creating social good as well as business success.” – Mark Hurd, Oracle CEO
Machine learning, at its core, is the practice of making intelligent computer systems that can learn automatically from experiences. These experiences or to say, data constitutes the foundational grounds of machine learning algorithms or sets of rules. With the world generating over 2.5 quintillions of data each day, machine learning algorithms are growing stronger for-
a) Solving complex problems
b) Making predictions
c) Improving performance
d) Formulating strategies, and a lot more.
Contrary to traditional computer programs, machine learning algorithms are able to learn autonomously from rich data without being explicitly programmed. It is on the basis of data availability that we categorize machine learning into four broad types-
1) Supervised Learning
Data is labeled, i.e. clearly annotated with output for the ML model to train its algorithms. Under supervised learning, ML models are fed with examples tagged with exact answers that the algorithm should fetch on its own.
For instance, a labeled dataset of fruits would first train the model with distinct images of apples, bananas, et al. Once trained, the model should be able to predict correct fruit names in a different image.
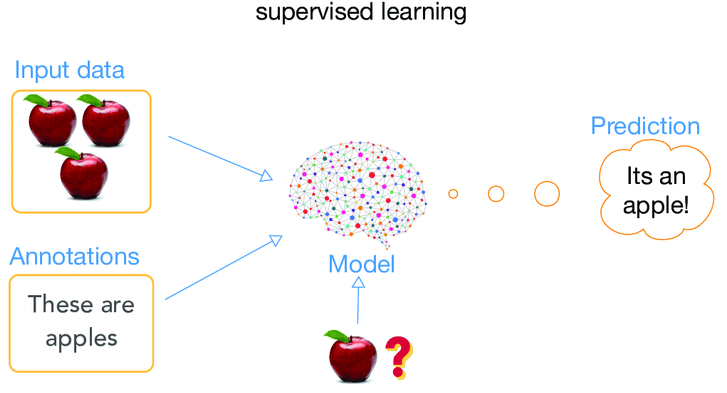
Classification, regression, and forecasting are the types of ML algorithms applied under supervised learning.
2) Semi-supervised Learning
Data is both labeled and unlabeled. While labeled data provides annotations for essential data, ML algorithms learn from the labeled inputs to label the unlabeled data. The methodology is gaining significant success in extracting relevant features from complex and labor-intensive datasets.
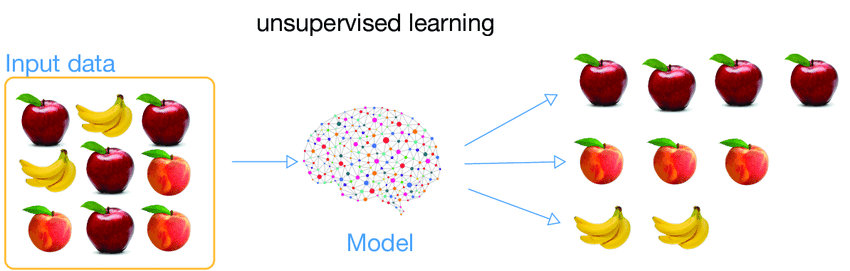
3) Unsupervised Learning
Data is completely unlabeled and the algorithms train to identify patterns and logic behind the data to draw inferences. Without any specific output to achieve, unsupervised learning models use different techniques such as clustering, anomaly detection, association, autoencoders to organize data and extract value.
4) Reinforcement Learning
Data is unstructured and undefined, representing an environment wherein ML algorithms are given certain actions, parameters, and end value. Similar to a video game scenario, under reinforcement learning, algorithms are encouraged with rewards and cues to fight to find value by defining their own rules and strategies.
Having understood machine learning holistically, let’s dig deeper into the brains behind innovative AI solutions, i.e. machine learning algorithms.
Also read- AI Explained: Rule-based AI Vs Machine Learning for Enterprises
Top 5 Machine Learning Algorithms and Their Enterprise Applications
1) Linear Regression
Linear regression involves understanding the linear relationship between a dependent and independent variable. The independent variable explains factors impacting the dependent variable that in turn acts as the predictor.
Created by Francis Galton in the 1800s, linear regression was used to find the relationship between the height of fathers and their sons. Eventually, the algorithms gained momentum to gauge prices, risks, sales, and other values. The mathematical representation of this algorithm is written as-
Y = a + b*X
Here, Y is the dependent variable, X is the independent variable and a and b are constants representing the intercept and slope respectively.
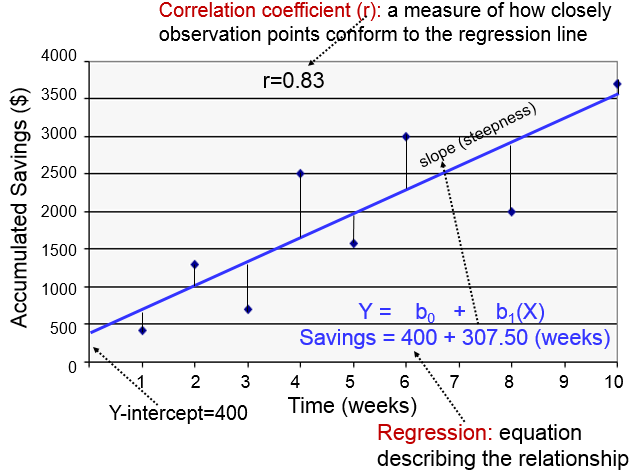 Linear regression algorithm enables machines to estimate the Y value with respect to X without any knowledge of the Y value in advance.
Linear regression algorithm enables machines to estimate the Y value with respect to X without any knowledge of the Y value in advance.
Potential Machine Learning Applications Using Linear Regression
With the Oodles’ AI team, businesses can implement linear regression using Scikit-learn and Python to build result-oriented applications, such as-
a) Risk Assessment- With quick and easy implementation, linear regression can strengthen risk assessment for insurance and financial sectors for initiating effective preemptive actions.
b) Sales Forecasting- For businesses, linear regression can be an effective means of deploying ML models for estimating sales based on product price, operational cost, etc.
Also read- How Artificial Intelligence in eCommerce is Embracing the New Normal
2) Logistic Regression
Unlike value estimation, logistic regression works on the principles of probability to categorize data into the given groups. For instance, whether emails are spam or not, whether the patient is prone to a certain disease, et al. Simply put, logistic regression is best suited for classification problems involving the prediction of data labels based on explanatory factors.
Potential Machine Learning Applications Using Logistic Regression
a) For predicting loan defaulters and non-defaulters for banks and insurance houses
b) For segmenting diabetic patients from non-diabetic ones
c) For weather forecasting as being rainy, sunny, or cloudy
d) For differentiating fraudulent accounts from online accounts.
3) Decision Tree
Similar to a flow-chart, decision tree algorithms reflect a branched structure, wherein each branch represents a possible outcome for the input. Every node in the tree represents the test on the attribute and the leaf node represents a given class label or the final decision. The rules of classification are splayed across the path of the branch starting from the root to the leaf node.
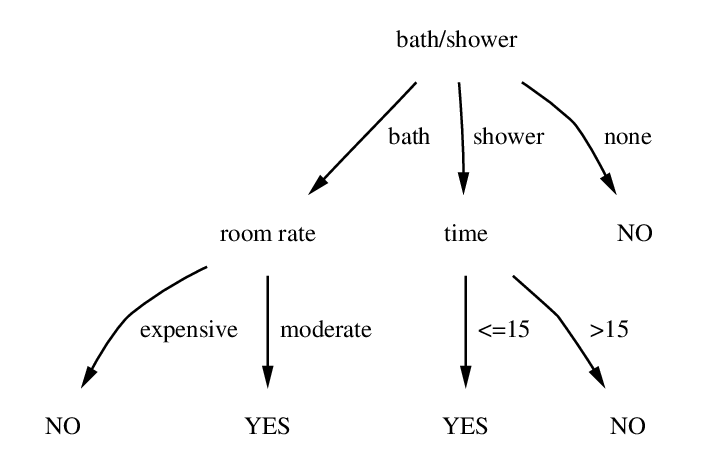 A visual representation of a decision tree.
A visual representation of a decision tree.
Potential Machine Learning Applications Using Decision Tree
a) For identifying disease patterns and patient conditions
b) For formulating marketing strategies for common audiences
c) For evaluating job security concerns for employees
4) Support Vector Machine
Again a supervised ML algorithm, support vector machine, or SVM is focused on solving classification and regression problems. It works by classifying the given dataset into two or more classes by plotting a ‘hyperplane’.
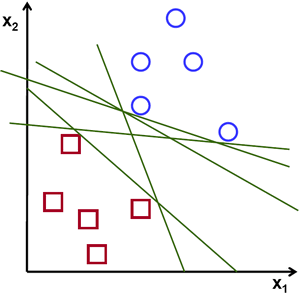
By incorporating maximum margins or distance, the SVM algorithm aims to identify the data classes with the highest accuracy.
Potential Machine Learning Applications Using SVM
a) For identifying facial features from non-facial features for surveillance
b) For categorizing simple text and hypertext doc files
c) For handwriting recognition
d) For stock forecasting, and more.
5) k-Nearest Neighbours
A classification algorithm, kNN works on a simple principle of classification based on the majority vote of an input’s k neighbors. Practically, it enables businesses to find out the characteristics of a certain client by analyzing all other kinds of clients that it trades with.
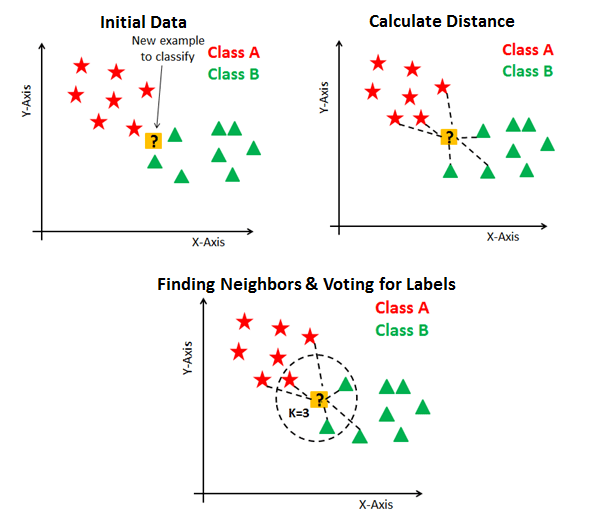 As shown in the image, kNN classification calculates the distance between variables and already classified data to annotate the unlabelled input.
As shown in the image, kNN classification calculates the distance between variables and already classified data to annotate the unlabelled input.
Potential Machine Learning Applications Using kNN
a) For compressing large datasets
b) For economic and statistical forecasting
c) For pattern recognition in complex datasets, and more.
Also read- Machine Learning and Augmented Analytics to Optimize Business Intelligence
Deploying Machine Learning Algorithms With Oodles
AI and machine learning are propelling business intelligence to build innovative solutions for several enterprise challenges.
We, at Oodles, are skilled professionals with working knowledge of different machine learning and its algorithms. Our AI team has hands-on experience in deploying top-notch machine learning algorithms for serving dynamic business use cases, such as-
a) Facial recognition for employee attendance
b) Diabetes prediction model
c) COVID-19 risk assessment chatbots
d) Image caption generator, and more.
In addition to machine learning, we provide custom chatbot development services using NLP algorithms.
Join forces with our AI development team to build data-driven AI applications.




