
MobileBERT
Posted By :Ashish Bhatnagar |12th April 2021
MobileBERT:Compressed version of BERT for resource-limited devices
Recent years have been astonishing in terms of breakthroughs in the Natural Learning Process (NLP). Machine Learning Industry and Data Scientists are focusing on the training of Bigger and Better models. These model achieve almost near-human performance, but they are usually too big to be deployed on devices with constrained resources like a mobile phone, a drone, etc.
BERT stands for Bidirectional Encoder Representations from Transformers, a similar NLP framework developed by Google that significantly altered the NLP landscape.
But one of the significant obstacles to the broader adoption of AI in our everyday lives remained the same, i.e. they were too big to be deployed on various devices.
What is MobileBERT?
MobileBERT is a slimmed version of BERT_LARGE augmented with bottleneck structures and a diligent design that balances self-attentions and feed-forward networks.
MobileBERT a better alternative?
We use a Bottom-to-top progressive scheme to train MobileBERT to transfer the intrinsic knowledge of a specifically designed Inverted Bottleneck BERT_LARGE.
Many studies have proved that MobileBERT is 4.3x smaller and 4.0x faster than the original BERT-BASE while delivering competitive results on well-known NLP benchmarks.
It is difficult to accept that a framework, which is 4.3x smaller in size than the original model, can achieve almost the same benchmark results without losing out much on accuracy and performance.
Well, this is what we are going to discuss in this blog.
How was MobileBERT created?
It's always challenging to train such a deep and thin network. To overcome the limitation of the training issue, we first construct a Neural network called Teacher Network and train it until convergence, then conduct knowledge transfer from this Teacher network to MobileBERT. We infer that this is a lot better than directly training MobileBERT right from scratch.
Strategies used to create MobileBERT.
Let's look at some of the strategies the MobileBERT model has used, by which it achieves equivalent results from the original BERT model.
Optimizations: Whenever it comes to speed or latency, coming up with better optimization strategies is crucial.
These two variations helped the Mobilebert model achieve a better result:-
- Remove layer normalization. We replace the normalization layer of an n-channel hidden state with an element-wise linear transformation.
- Use RELU activation. We substitute the Gaussian Error Linear Unit(GELU) activation with a more straightforward Gaussian Error Linear Unit(RELU) activation.
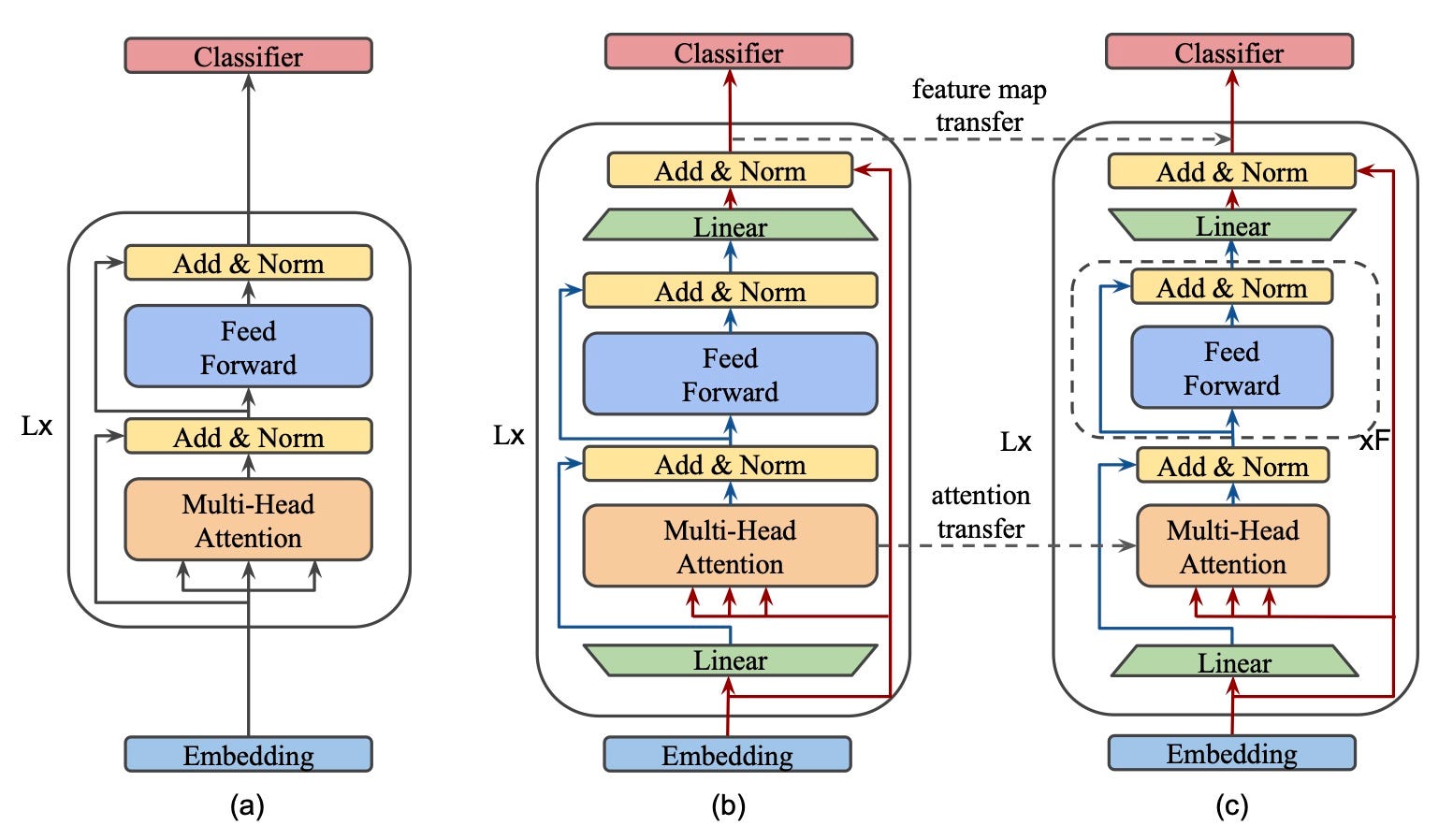
Source: https://www.aclweb.org/anthology/2020.acl-main.195
Training Strategies: This is the backbone of any deep neural network model. We want our model to converge faster and better with the utmost accuracy.
Some of the unique strategies which are used in MobileBERT to achieve that are:
- Auxiliary Knowledge Transfer: They regard intermediate knowledge transfer as an auxiliary task for knowledge distillation. They used a single loss, a linear combination of knowledge transfer losses from all layers, and the pre-training distillation loss.
- Joint Knowledge Transfer: They divided the process into two steps. First, we train all layer-wise knowledge distillation losses until convergence and Second, we perform further training with the pre-training objective.
- Progressive Knowledge Transfer: Instead of training all layers at once, they train one layer at a time while freezing or reducing the learning rate of previous layers.
Use of Quantization method in MobileBERT
MobileBERT has also introduced model Quantization, which brings the deep neural network to a reasonable size while also maintaining high-performance accuracy.
Let's understand Quantization in detail.
In this strategy, we apply the standard post-training quantization. While Quantization can further compress MobileBERT 4x, there is almost no performance degradation. This result indicates that there is still scope in the compression of MobileBERT.
Further, the results also show that this holds in practice too, as MobileBERT can reach 99.2% of BERT_BASE's performance on GLUE with 4x fewer parameters and 5.5x faster inference on a Pixel 4 phone.
Empirical results on popular NLP benchmarks proved that MobileBERT is comparable with BERT BASE while being much smaller, faster and performance efficient. MobileBERT can enable various NLP applications to deploy on mobile devices quickly.
Ready to innovate ? Let's get in touch

Follow us


We are ISO 9001:2015 Certified
Resources

Connect with us

Follow us
![]()
![]()
![]()
![]()
![]()
![]()
![]()